Beyond the Hype: Generative AI Trends that Really Matter

Something unreal has happened with Chat-GPT, it took 5 days for the app to reach a million users and two months to reach 100 million users. Unlike other disruptive enterprise technology trends of the past — internet, containerization, cloud, traditional AI etc. Transformers and Large Language Models (LLMs) has a killer-app unlike any other for the masses. This tangibility, however, has been a dual edged sword - on the one hand it has made LLMs more accessible to non-technical users, on the other it has lead to an overestimation of it’s potential impact.
Software companies, investors and enterprises are dropping everything to figure out implications of Generative AI. Strategies are being re-hashed, product are being re-designed, new use-cases are emerging across functions like software development and marketing, some industries like media, legal, education etc. are contemplating what this means for their future. Through all this frenzy, new companies are mushrooming like the dot-coms pre-2001s.
Foundation models are not a recent concept, popular CNNs like Resnet-50 was first released in 2015 and the higher level language and image APIs, NLP platforms and chatbots have been around for a decade. While transformer architectures and “attention” have created a paradigm shift in performance, it is important to separate the hype from reality and acknowledge that certain claims about the capabilities of LLMs are nothing short of unrealistic.
The key question is what key trends really matter in Generative AI, and what it all means.
Generative AI is getting rapidly democratized at the foundation model and platform layers
Like traditional AI, Generative AI is increasingly becoming more accessible to smaller companies outside big-tech and enterprises, driven by four reenforcing trends —
- Inflow of private capital from VC/PE funds
- Community and open source driven innovation
- Big-tech investments across the stack — Hyperscalers in platforms; SaaS players at the application layers
- Rapid technological advancements in model architectures, AI hardware and software stacks e.g. GPUs and frameworks like Pytorch, and training techniques making LLMs more accessible (covered later)
Despite a relatively cautious deal market, a massive amount of money that has gone into generative AI — $1.7 billion 46 deals in Q1'23 alone, not including the $10B investment from Microsoft in OpenAI.

We are seeing multiple commercial foundation models including well known ones like Open-AI GPT-4, Google PaLM-2, but also from upstarts like Anthropic Claude, Cohere, AI21 Jurrasic-2, just to name a few.
The real activity, however, is happening in the open source community. With over 200K models 36K datasets Hugging Face has become one of the fastest growing communities and open source projects on GitHub, growing faster than Kubernetes. Multiple open models have emerged including Bloom, GPT-Neo, LLaMA, Vicuna, Pythia amongst others, and newer ones are coming up almost on a weekly basis.
Beyond foundation models, platform libraries have seen a lot of innovation. The community has coalesced around libraries like Transformers and LangChain, which provide higher level abstractions, wrappers and adapters for multiple models, making it easier and more flexible to experiment with Generative AI. What is really interesting are features like Agents and Tools which provide natural language interfaces and composability for these APIs.
Big-tech is attacking Generative AI at multiple levels. In addition to higher level language services like AWS Rekognition and Textract, every cloud vendor has either enhanced their AI platforms e.g. Google Vertex, or added new services e.g. AWS Bedrock to support building and deploying LLMs. In an effort to capture the hybrid and on-prem markets, IBM announced WatsonX last month, and Nvidia which is well positioned to benefit from a surge in GPU sales, has made a strategic decision to move up-stack with its AI foundations and NeMo service, which is now available for early access.
All these trends are rapidly democratizing Generative AI. Today, you can start from scratch, train, and deploy a custom tuned LLMs in a matter of hours. There are already approximately 500 generative AI companies according to NY times, and this number is continuing to grow rapidly.
While platform commoditization was expected, what is more interesting are moves from the larger SaaS players, who are actively building custom LLMs and directly integrating Generative AI into their products e.g. Microsoft Copilot 365, Salesforce Einstein GPT, and recent announcements like Adobe integrating Firefly into Photoshop, Servicenow + NVidia partnership for IT workflows and automation.
The evolution here is very similar to what happened in the early days of AI. Competition is increasing at all layers, but platform layer is getting increasingly commoditized. Competitive advantage still comes from two things (1) owning or having access to high-value data, and in many cases integration into existing systems of engagement and record and (2) economic advantages in training or inference (deep dive ahead). While there are advantages to being an early entrant, any early technological advantage in models or platforms is not sustainable.
We are hitting scale limits of LLMs — cost and economics is a major vector of innovation and competitive advantage
In 2018 BERT was the largest transformer model with 350 million parameters, today’s modern LLMs like Google PaLM and GPT-4 have 540B and trillion parameters respectively, this is a ~3000x increase in 5 years.
The costs of training these models has ballooned, there are various estimates out there — training costs alone are anywhere from ~2M for a smaller model of 1B parameters to a upwards of ~$10–20M for larger models of 300B parameters. But the overall cost is not a function of the number of parameters alone, but also the number of tokens or size of the data needed and the compute cost/FLOP.

As models get bigger, so does the amount of data required to train them optimally, as shown by this excellent paper from Deep Mind. The study from Deep Mind showed that a lot of these mega foundation models are undertrained and Deep Mind’s Chinchilla model with 70 billion parameters, trained on 1.3 trillion tokens outperforms other larger models including Gopher, a 280 billion parameter model. For modern models that are already at about 1.6 trillion and fast approaching 5-10 trillion parameters, the total costs can be astronomical — by some estimates in 100s of millions of dollars, driven by many challenges:
- Availability of quality data corpus.
- Hardware limitations and utilization limits caused because of memory e.g. loading and manipulating a trillion parameters into memory is a bigger challenge than compute.
- Performance and costs of inferencing. Larger models equally expensive to run inference on. There is an excellent article that analyzes the costs of running GPT-3 at 1–5 cents per chat, which will explode once you extrapolate to larger models.
The costs are driving an enormous focus today on cost engineering and optimizing models for cost effective training and inference. Several techniques have emerged:
- Newer model architectures e.g. leveraging “sparse” vs. “dense” models i.e. training models where nodes are not fully interconnected to each other, reducing the number of parameters required e.g. Google GaLM is 7x larger than GPT-3 but requires 66% less energy to train
- Performance optimization and vertical integration in compute and AI software stacks e.g. Pytorch with “operator fusion”, GPUs with 3D NAND Flash, specialized silicon like TPUs etc.
- Parameter Efficient Fine Tuning (PEFT )— see ahead
- Quantization and mix precision training or training and running models at lower numerical precision e.g. 8 bit vs. 16 or 32 bit
- Model pruning or removing parameters without equivalent drop in performance
While algorithmic and model architecture improvements, Moore’s law and silicon optimized AI stacks should push costs down overtime, adoption will always be a function of economics. A lot of larger models may not be economically viable for industry use-cases. Engineering and innovation in the future will be focused on building highly customized models, which are optimized for price/performance for that use-case, or creation of multiple “fit for purpose” models — much like VM instances on cloud providers. Next time you see a demo that is running sentiment analysis using GPT-4, just question the logic and viability of that engineering choice.
Developments in Parameter Efficient Fine Tuning (PEFT) is lowering barriers to tune models, accelerating innovation
Sam Altman, the CEO of OpenAI, recently mentioned that the era of large models is over and the focus will now turn to specializing and customizing these models. Real value is unlocked only when these models are tuned on customer and domain specific data. Re-training LLMs, particularly larger models, on custom data from scratch is economically not feasible and inefficient. To get the most bang for your training buck Parameter Efficient Fine Tuning (PEFT) has exploded as a research area in LLMs, and there are multiple methods that have emerged.
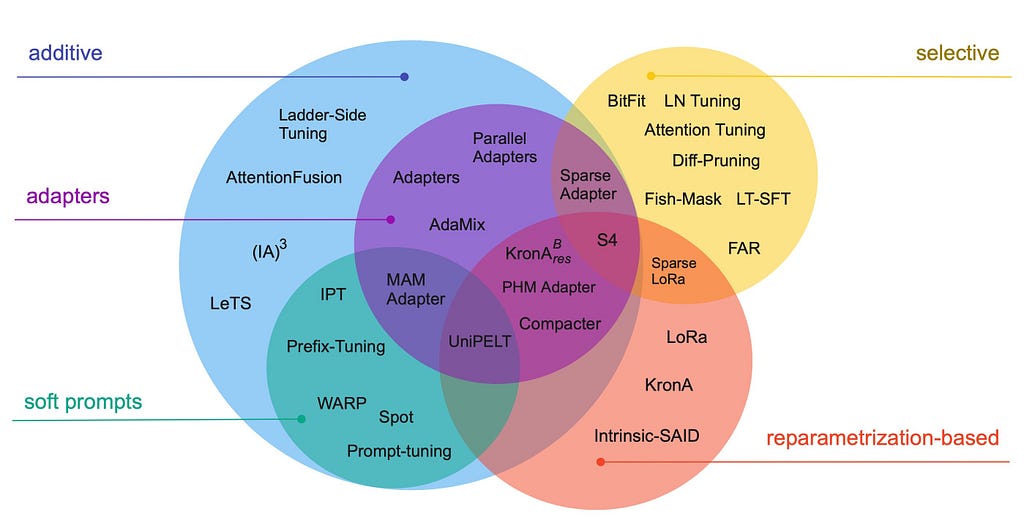
- Additive tuning refers to adding layers or parameters to existing models for training. Adapters like the LLaMA adapter introduces 1.2M parameters, and enables tuning LLaMA to tasks in about an hour of training. Prompt tuning is another method where input prompts are engineered to adapt models. Both approaches have shortcomings — adapters add lag and prompt tuning is unpredictable.
- Selective tuning pre-selects the parameters of an existing model to train vs. adding more parameters. These might be layers within models or preselected parameters.
- Re-parameterization trains with lower rank representations (think smaller matrices) to reduce the number of parameters being trained. One particularly elegant technique that has emerged is LoRA (Low Rank Adaptation). There are two things that make LoRA transformative — first the tuning gains relative to the number of parameters is almost unbelievable — there a few examples out there of tuning Bloom in under half hour; the second is that architecture allows you to swap our update matrices in runtime, making their use extremely flexible.
The reality is that newer methods are emerging daily which are a hybrid of the above approaches. The impact of techniques like LoRA is that it’s fundamentally shifting the economics of tuning, lowering the barriers, and accelerating the commoditization of Generative AI.
The now famous leaked document from Google recognizes these trends. It asserts that closed-model players like OpenAI and Google don’t have a moat, and that the open source community will “eat them for lunch”. When you juxtapose PEFT with the open models like Vicuna, model hubs like Hugging Face and open source libraries like LangChain, it’s a great equalizer for the community.
While our models still hold a slight edge in terms of quality, the gap is closing astonishingly quickly. Open-source models are faster, more customizable, more private, and pound-for-pound more capable. They are doing things with $100 and 13B params that we struggle with at $10M and 540B. And they are doing so in weeks, not months. — leaked Google document
If this arc continues, it has profound implications. First, it will erode the perceived advantage that closed-source models have today, and will likely steer engineering teams to use open source models with well understood and economical tuning patterns and libraries. Second, it will accelerate the proliferation of domain and vertical specialized models. Third, it will also impact the IaaS, HPC and silicon industries betting on Generative AI workloads, since a lot of enterprises will leverage open source models and PEFT based fine-tuning instead of building and training large models. Most importantly however it empowers individual developers and smaller companies to innovate quickly and at lower costs, by creating the same dynamics as cloud did for software development fifteen years ago.
The next wave of innovation is already underway with a shift from LLMs to mega sized MLLMs (Multimodal large language models)
Current language models are still very language and text focused. One potentially game-changing development is MLLMs, or models that support text, in addition to other modalities like audio, and images. Open AI GPT-4, Google Palm-E and Microsoft Kosmos-1 are a few examples of such models. These models are more complex to build, tune and test. Kosmos-1 for example has 1.6 trillion parameters and trained on a complex “web scale” data set. But this complexity also allows these models to solve very high value use-cases in robotics, perception and OCR free language tasks, and many more use-cases of the future.

We are still early days here. It will be interesting to see what new models emerge, and how tuning techniques and economics of these models will evolve.
Enterprises have limited “at scale” adoption, and penetration of Generative AI might be slower than most think
The use-cases of LLMs and Generative AI are relatively well understood now. While a lot of companies have started PoCs, adoption and prioritization of Generative AI varies significantly by vertical.
Despite the hype, there are companies that are playing the waiting game. In one very recent survey from KPMG two out of three enterprise executives say that they are still 1–2 years away from adopting a generative AI use case.
There are seven main challenges that are preventing enterprises from going all-in.
- Lack of a clear strategy — Absence of a clear strategy and well-defined business cases that highlight the value and benefits of generative AI in specific contexts e.g. the cost of building a data corpus, tuning etc.
- Data gaps and costs — In a recent BCG study, we learned that most enterprises today are struggling with basics — legacy and fragmented data architecture, spiraling data costs, no governance etc. and this is creating a significant barrier to adopt all AI — traditional and generative.
- Talent — Not surprisingly talent and skills continues to be a top barrier to adopting AI more broadly.
- Risks in Foundation Models — There are many well documented risks and unknowns about foundation models e.g. IP and legal, cybersecurity, bias and toxicity, and the ethical challenges which aren’t fully understood.
- External Regulation —regulation is a major factor driving adoption and ultimately the technological impact in certain verticals like healthcare and banking, as well as public safety related use cases e.g. autonomous driving.
- Change management — In the classic 70:20:10 BCG framework, organizational change is 70% of total investments required to adopt AI at scale, 20% in technology and only 10% in algorithms. Technological advancements like transformers will open up new use-cases, but won’t change these physics. Successfully navigating the organizational, cultural and business process shifts necessary for embracing generative AI is crucial, and often underestimated.
- Relatively high cap-ex of on premise generative AI hardware
Despite its game-changing potential, time will tell how quickly we see at-scale adoption. If there is anything we have learned from past technology cycles like cloud and traditional AI, is that some of these structural problems are difficult to untangle, and the inertia of change is very hard to overcome.
There are three takeaways for software companies, enterprises, investors and advisors.
Takeaway 1— Take current claims with a grain of salt, evaluate use-cases and impact in your context: There are generative AI use cases today which are consumption ready, with task-dependent and variable efficacy e.g. code assistants like Github Copilot and writing tools like Jasper. But, a lot of the claims of Generative AI’s impact and numbers today is conjecturing, hype and speculation based on very little evidence. LLMs aren’t a silver bullet and have their limitations. Domain specific use-cases are only as good as the data used to train them, and in many LLM pilots the results suboptimal and often incorrect. Google Bard’s less than spectacular debut is a good reminder that companies must remain balanced and evaluate the use-cases.
Takeaway 2 — Competitive advantage is not a function of models, but data access and finding the balance between price and performance: There will continued platform and foundation model proliferation, and democratization of technology. If you peel the layers of the onion there are two moats and differentiators —
- Data and data integration: labeled and curated domain specific data has quickly become the strategic control point and companies like Salesforce and ServiceNow are well positioned and betting on their own content to build next-gen features. Availability of a quality corpus is also quickly becoming the gate to train larger models and MLLMs. Just like in traditional AI, owning or having access to proprietary data is the biggest moat.
- Costs and economics: To develop an intuition of why Generative AI might not make sense for every use case, consider this one extreme example - if Google runs modern large LLM for search, it will dent profits by approximately 10B/year using conservative assumptions. Winners will focus engineering efforts on finding the optimal cost/performance frontier, and sometimes that might mean not using Generative AI at all, at least for now.
Takeaway 3- Don’t buy into the fear mongering — the window does not close if you don’t invest in Generative AI today: Counterintuitively, it might be better to have a higher bar for building vs. buying during the early days of high technology risk. Experiment and evaluate use-cases, but wait for the dust to settle before investing millions in wrong technology and platform bets, failed pilots and products. There are exceptions of course e.g. if you operate in a product category that is getting disrupted (language APIs, NLP platforms, chatbots etc.) moving immediately is an imperative.
It’s hard not be excited about the potential impact transformer architectures and LLMs can create for society — productivity gains, transformed industries etc. But it’s equally important to to take a balanced view, and acknowledge the limitations and reality of today. First, the technology is far from perfect, has inherent risk and in some cases economically not viable. Second, a lot of enterprise customers might not be ready to change soon. Like technology cycles in the past, hype will always precede practicality and one must go through a trough of disillusionment before moving up the arc of enlightenment.
Welcome on-board — the ride has just begun!