I Tried to Build the Perfect AI System. Here’s Where Conventional Wisdom Was Wrong.
A practitioner’s post-mortem. Not a setup guide.
About a year ago I decided to stop reading about AI systems and start building one — specifically, one that could manage the full complexity of my life. Professional threads, networking, alumni connections, family planning, real estate research — the kind of cognitive load that accumulates when you are trying to be deliberate about decisions and relationships across a dozen different contexts simultaneously.
I gave myself one constraint: no patience for latency, shallow answers, or bloated costs. This had to actually work for me.
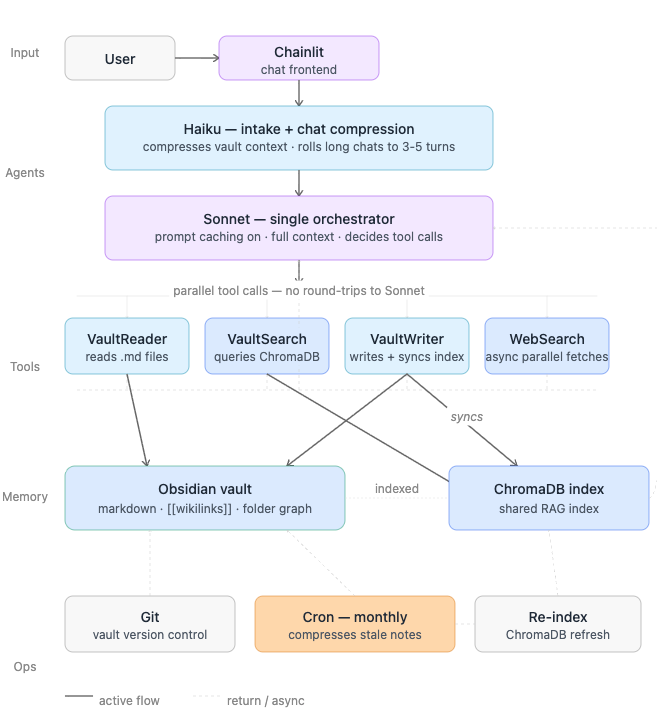
What followed was a year of building, breaking, and rebuilding — starting with LangChain, moving to CrewAI, experimenting with open-source models, and eventually arriving at something that works so well I am slightly embarrassed by how simple it is. The architecture is two layers: Haiku as Executive Assistant, Sonnet as Chief of Staff. Stack: Python, Chainlit, Anthropic Sonnet and Haiku, Google Gemini Flash, ChromaDB, Obsidian.
Three things I thought I knew turned out to be wrong. The same mistakes show up constantly in enterprise AI deployments.
More Agents Does Not Mean Better Reasoning
When I moved from LangChain to CrewAI, I built what the framework encourages: five agents. Chief of Staff for orchestration. Vault Agent for my knowledge base. Research Agent for web search. Synthesis Agent. Routing Agent. Clean separation of concerns, each model doing what it was cheapest at.
While I was at it, I experimented with open models to control cost. KimiK2 made factual errors on structured tasks and was less reliable than even Haiku. DeepSeek V3 Pro as the main orchestrator surprised me — the reasoning and writing held up better than I expected. Still, I came back to Sonnet. When the system is handling work that actually matters, the reliability delta is real.
None of it fixed the fundamental problem: five-agent output was poor and expensive. Not marginally — noticeably worse, at significantly higher cost. I spent weeks tuning prompts before I realized it was not a prompt problem.
Every agent handoff is a context truncation event. When the orchestrator delegates to the Vault Agent, it compresses the full context into a prompt the cheaper model can act on. That model executes on the compressed version. The result returns. The orchestrator integrates it and hands off again. Five agents, four truncation events per query — and at each boundary, the nuance and competing considerations that make a judgment call hard get stripped out. The cheap model does not execute more slowly. It executes on a degraded version of the problem.
A frontier reasoning model already does internally what the multi-agent pipeline does externally — breaks down problems, considers sub-problems, synthesizes — without the context loss. You are building expensive infrastructure to replicate what the model does natively for free.
I collapsed to a single Sonnet agent and turned on prompt caching. Both problems dissolved. Output quality jumped. Cost dropped by more than half — cache hit rates landed between 40–60% depending on query patterns, which translated to roughly a 50% reduction in token spend. A simple query runs under five cents. A heavy multi-tool query with vault reads and web search runs under a dime. Cold starts add a couple of cents. For a system I use dozens of times a day, the economics only work because of caching — the system prompt, vault context, and repeated reference material cache across follow-up queries, which is the natural rhythm of how I actually work. Haiku compression on long conversation threads and chat history saves another 30–50% on input tokens before Sonnet ever sees them. The savings compound in a way that does not show up in per-query math. Watch the monthly dashboard.
This is not just empirical. Tran and Kiela’s Stanford paper tested single and multi-agent systems with identical reasoning token budgets across three model families. The single agent matched or outperformed multi-agent in nearly every condition. The theoretical backbone is the Data Processing Inequality: every inter-agent handoff can only lose information, never create it. The paper’s quieter finding: single-agent prompts with explicit pre-answer analysis recover most of what looks like a collaboration benefit in multi-agent traces. The collaboration was not the source of the gain. The extra thinking was. You can have the extra thinking without the extra agents.
Separation of concerns is a design concept. Not an execution requirement.
One exception I made proves this rather than breaks it. I front every chat with Haiku — which violates the single-model rule. But Haiku’s job is mechanical: read incoming context, compress vault state, roll long conversation threads into essential facts. Signal extraction, not reasoning. Haiku does it for 1/8th the cost, and by the time Sonnet sees the input, the problem is already sharp. The exception works because it is scoped — a cheap model handling mechanical intake before the expensive model reasons. The moment you use cheap models for judgment or routing — the way the five-agent architecture did — cost savings evaporate into quality loss. The rule holds. The exception is the proof.
The Graph You Design Is Not the Graph You Need
First instinct was a relational graph. People, threads, decisions, dates — these feel like entities with clear relationships. I stood up Postgres on Supabase with PG-based RAG, designed a schema, built traversal logic. It worked. But it was clunky and unnatural. Threads got linked to milestones and goals when the relationship was not clean. I kept writing exception logic to handle cases where the schema forced connections that did not reflect reality. The system was technically functional and practically brittle — I was working around my own data model more than I was working with it.
The deeper problem was rigidity. In a relational schema, you always traverse the same paths: contacts to events, goals to TODOs. But what if a networking conversation surfaces someone relevant to a completely different thread — a real estate search, a college planning question, a professional decision you are weighing? What if someone you met at a conference has a kid applying to the same schools as your daughter, and that context changes how you follow up? Those connections are hard to capture in a schema you designed before you understood what mattered. You end up either missing them or building ever-more exception logic to force them in.
I moved to Obsidian reluctantly. Markdown files with [[wikilinks]] are a graph database with different tradeoffs - and those tradeoffs fit the problem. Wikilinks are bidirectional and emergent. Write a thread note, reference a person - that person's note knows about the thread without you designing the relationship. The graph builds itself from the act of writing. What you get is a graph whose topology reflects how you actually think, not how you thought you would think when you designed it. At 40-50 active threads, the flexibility advantage is real. Whether it holds at enterprise scale with hundreds of contributors is a different question.
Here is how retrieval actually works: I search ChromaDB, pull the matching documents, then follow the wikilinks to pull related documents at configurable depth — n=1 works well for me. So a query about a professional thread does not just return the thread note. It pulls in the linked people, the history of my interactions with each of them, what we last discussed, their context. A query about college planning pulls in the schools, the deadlines, the people in my network who went there or have relevant experience. That context arrives together because the links exist naturally in the notes, not because I designed a join path. This is what makes the system’s reasoning rich — the model sees the full ecosystem around a topic, not an isolated document.
Research comparing RAG and GraphRAG confirms this gap: flat RAG is stronger for factual queries, while graph-aware retrieval outperforms on reasoning-intensive questions requiring synthesis across multiple sources. For a personal knowledge system where most queries are the latter, the difference is significant.
Your data model should match your read operation. LLMs read text natively.
Accumulation Is Not Memory
This failure took months to see because it looked like the system working.
The vault was growing. Every interaction added context. Every thread got richer. Then I noticed responses to current questions were being diluted by resolved context from months ago. A thread that closed in January was surfacing alongside an active thread from last week at equal retrieval weight. The system had no sense of recency. It had storage. Not memory.
The research explains why this is damaging. Liu et al.’s “Lost in the Middle” study showed performance drops of over 30% on multi-document QA when the answer was buried in position rather than at the edges of context. An accumulating vault without recency weighting does not just add noise — it actively buries the signal you need.
I built a monthly cron that scans notes older than 30 days and compresses them. Not summarization — it extracts what persists. Decisions made, outcomes, context still load-bearing for current threads. A 900-word resolved thread becomes 150 words. Specifics go. Signal stays.
Retrieval quality improved immediately. The system started feeling like it was thinking about what is happening now.
I want to be transparent: selective compression is something I will keep refining. Getting the model to reliably distinguish load-bearing context from resolvable detail is genuinely hard. I think this is the core unsolved problem in AI memory management. What I have is a working approximation that compounds over time.
Compression is not deletion. The information I lost was noise in the retrieval signal. And there is a second-order effect: the cron is not just memory hygiene. It is a forcing function that asks, every month, what from this period is still load-bearing. That question, asked regularly, sharpens the whole system.
Memory has recency semantics. The forgetting curve is not a limitation to work around. It is a feature to replicate.
The Pattern Underneath All Three
Every failure was the same mistake in a different domain. I optimized for engineering tidiness — structured schemas, clean agent boundaries, ever-growing context — when the system I needed was optimized for how reasoning and memory actually work.
The cost of architectural complexity in AI systems is paid in reasoning quality, not just latency and dollars. That trade is invisible until you collapse the complexity and see what the model can do when you stop getting in its way.
I am hooked on this setup. Not because it is elegant. Because it works.